数据库概览
数据库技术
- 数据库及有关概念
- 数据模型
- 关系数据库
- 关系代数
- SQL查询等语句
- SQL中增删改查数据
- 设计数据库
数据库及有关概念
- 数据库所经历阶段
- 数据库特点
- 内部体系
- 外部体系
- 三个世界
- 实体型之间联系
人工管理阶段
- 主要用于计算,没有磁盘之类的直接存储设别。
- 数据不保存,计算完成即释放。
- 没有专门管理数据的软件。
- 数据不能共享,数据面向程序。
- 数据不具有独立性。依赖于应用程序
文件系统阶段
- 用于科学计算和信息管理。
- 有磁盘,磁鼓等直接存储设备。
- 出现文件系统:专门管理数据的软件
- 反复利用,增删改查。
- 有一定的共享性
- 但仍然是面向应用的,文件之间相互独立。缺乏联系
数据库系统阶段
- 出现大容量、存储快速的磁盘。
- 实现了数据结构化,面向全组织的所有应用
- 共享性高、冗余度低:一组数据集合可以为多个应用和多个用户使用
- DBNS:数据库管理系统来实现各个应用程序对数据库中的数据共享
- 独立性高。
下面重点介绍数据库系统阶段。
数据库系统的特点
- 数据库结构
- 数据独立性
- 安全性控制
- 完整性控制
- 并发控制
数据库结构
- 数据库结构是指:用户的逻辑结构、数据库逻辑结构和物理结构。
数据独立性
- 数据独立性指:物理独立性和逻辑独立性。
- 独立性都是指当改变了物理结构和逻辑结构后,用户的逻辑结构和应用程序不用改变。
- 物理:存储结构,存取方式,外部的设备。
- 逻辑:数据库的逻辑结构(数据类型,数据关系)
安全性控制
合法用户只能操纵有权限的数据。
完整性控制
设置额完整性的约束条件
并发控制
防止相互干扰数据库收到的损害
数据库系统(DBS)
利用计算机对数据库中的数据进行管理
组成:计算机硬件、数据库、软件系统(操作系统,应用程序开发系统、数据库应用系统等)、DBMS(数据库管理系统)、数据库用户。
数据库:将数据组成数据库形式对其进行存储、管理、处理和维护数据的高性能的信息处理系统。
数据库用户:对数据库进行存储、维护和检索操作
- 非计算机专业用户:利用接口实现
- 应用程序员:设计和编译应用,实现调试安装
- 数据库管理员(DBA):设计、简历、管理和维护数据库
软件:操作系统、数据库管理系统、应用开发工具、数据库应用系统。
DBMS(数据库管理系统):
定义:提供定义语言。定义数据的模式、外模式、内模式三级模式结构。
定义模式/内模式和外模式/模式二级映像
定义相关约束
操纵:增删改查
管理:安全性、完整性、并发性、数据库恢复
等等
内部体系(三级模式结构)
应用<->外模式<->外模式/模式映像<->模式<->模式/内模式映像<->内模式<->数据库
- 模式:概念模式,是数据库中全体数据的逻辑结构和特征的描述,是数据库的整体逻辑(概念视图、概念数据库)
- 外模式:子模式或用户模式,处于最外层,用户能看到并允许使用的一部分局部数据的逻辑结构和特征描述。(用户视图、用户数据库)
- 外模式是模式的子集,可以有多个,一个外模式可以为多个应用程序使用。
- 内模式:存储模式或物理模式。对整个数据库存储结构的描述,内部的表述方式(物理数据库、物理视图)
- 一个数据库只有一个内模式
总结三种模式:用户根据外模式进行操作,通过映射与概念级数据库联系起来,又通过映射与物理级数据库联系到一起。
- 二级映像:DBMS在三级模式之间提供了二级映像功能,实现了数据的逻辑独立性与物理独立性
外部体系结构
- 单用户结构
- 主从式结构
- 分布式结构
- 客户/服务器结构、
- 浏览器/服务器结构
- 单用户结构:桌面型数据库系统:适合未联网用户、个人用户
- 主从式结构:大型主机带多终端的用户结构系统,又称主机/终端模式(过于依赖主机)
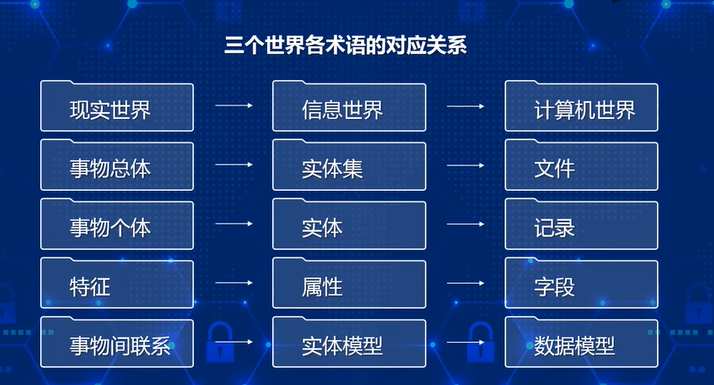
三个世界
- 现实世界
- 信息世界
- 计算机世界
图示表示更加清晰
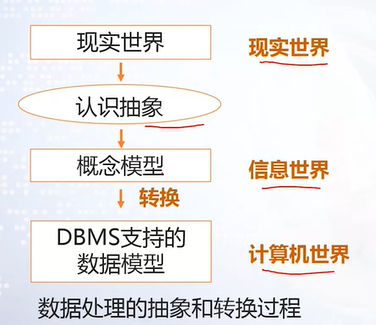
- 实体:客观存在并且可以相互区分。
- 属性:实体所具有的某一特征(具有属性名和特征值)
- 实体型:具有相同属性的实体必然具有相同的特征
- 表示方法:实体名(属性,属性)
- eg:学生(学号,姓名)
- 表示方法:实体名(属性,属性)
- 实体集:同型实体的集合称为实体集(所有的组成就是实体集)
- eg:所有学生
- 码:能够唯一标识一个实体的属性或者属性集的称为实体码
- 域:某一属性的取值范围称为这个属性的域
实体型之间的联系
两个实体型之间的联系就是指不同实体集之间的联系
- 一对一联系:实体集A中的一个实体至多和实体集B中的一个联系,反之亦然
- 一对多联系:实体集A中的一个实体可以和n个B中的联系,记为1:n,反过来,实体集B中的一个实体至多和实体集A中的一个实体联系。
- 多对多联系:实体集A中的一个实体可以和n个B中的联系,反过来,实体集B中的一个实体可以和实体集A中的m个实体联系 记为m:n
计算机世界所存储的数据模型
- 字段:标记实体属性的命名单位为字段,字段往往就是属性
- 记录:一个记录描述一个实体
- 文件:同一类记录的集合就是文件(实体集)
- 关键字:能唯一标识每一个字段或者字段集的就是关键字
- 数据模型:用来描述数据、数据联系、数据的语义和完整性约束的概念集合,由数据结构、数据操作、完整性约束三要素组成
- 数据结构:①描述数据库组成的对象有哪些②描述对象之间联系
- 层次结构->层次数据库
- 网状结构->网状数据库
- 关系结构->关系数据库(二维表表示)
- 数据操作:动态特性,①查询类操作②更新操作(插入、删除、修改)
- 完整性约束:数据及其联系制约及其依存的规则,保证数据的正确、有效、相容
(关系模型的数据操作是集合操作,对象和结果都是关系。操作接口简单)
关系数据库
关系数据库的码
候选码:能够唯一标识关系中元组的一个属性和属性集(唯一性,最小性
- eg:学生关系中,学号是候选码。
- 选课关系中,学号+课程号(属性集)是候选码
主码:从候选键中选择一个作为查询、插入、删除元组的变量
被称为主关系码(唯一的
- eg:学生关系中以学号作为数据操作的依据
外码:一个关系的的一个或者一组属性不是该关系的主码,但是另一个关系的主码。称为这个关系的外码,并称这个关系是参照关系。另一个关系为被参照关系
超码:包含候选码的属性集合
关系完整性
- 实体完整性
- 实体对于的是元组,元组的主码对应的是属性。
- 参照完整性
- 用户自定义完整性
关系代数
- 抽象的查询语言
- 运算对象与运算结果都是关系
- 关系代数运算符
关系演算
SQL查询语言
- 基本表
一个关系对于一个基本表,一个或者多个基本表对应一个存储文件
- 视图
一个和几个基本表中导入的表,是一个虚表,没有存储数据,只有定义。
- 支持三级模式结构
外模式对应基本表与视图
模式对应基本表
内模式对应存储文件
- 面向集合语言、一体化语言、非过程化语言
- 数据库的结构
- 从逻辑上来看:描述信息的数据存放在数据库中并存在数据库中由DBMS统一管理
- 从物理上看:描述信息的数据以文件的方式存储在物理磁盘上,由操作系统进行统一管理
- 数据文件(主要一个文件后缀.mdf,次要数据文件.ndf)、事务日志文件(.ldf)
- 创建数据库:
1 | CREATE DATABASE 数据库名 |
- 修改数据库
一、对象资源管理器中右键单击要修改的数据库,点击属性,在选项卡中进行修改
二、利用sql进行修改
1 | ALTER DATABASE 数据库名 |
例子:利用SQL命令修改数据库Teath,添加一个次要数据文件,逻辑名称为Teach_Datanew, 存放在E盘根目录下,文件名为Teach_Datanew.ndf。数据文件的初始大小为100MB,最大容量为200MB,文件自动增长容量为10MB
1 | ALTER DATABASE Teach |
删除次要文件:
1 | ALTER DATABASE Teach |
- 删除数据库
一、对象资源管理器中右键单击要删除的数据库,选择删除
二、sql命令
1 | DROP DATABASE 数据库名称 |
- 查看数据库信息
一、 对象资源管理器中,选中数据库,右击属性查看
二、 sql命令
1 | Sp_helpdb[[@dbname=]'name']//显示数据库的结构 |
- 迁移数据库
一、
- 分离数据库
在对象资源管理器中,选择要迁移的数据库节点,单击鼠标右键,在快捷菜单中选择“任务”,在之后的菜单中选择“分离”会弹出分离数据库的属性对话框
- 加载数据库
在对象资源管理器中选择“数据库”节点,单击鼠标右键,在快捷菜单中选择“附加”,会弹出“附加数据库”属性对框框(选择mdf文件)
二、 生成脚本
在对象资源管理器中,选择要操作的数据库节点,单击鼠标右键,在快捷菜单中选择“任务”,在出现的菜单中选择“生成脚本”,弹出“生成和发布脚本”窗口
创建和使用数据表
- 创建数据表
一、 右键单击“对象资源管理器”中的“数据库”节点下的“表”节点,从快捷菜单中选择“新建表”命令,会弹出定义数据表结构对话框,每一行用于定义数据表的一个字段,包括字段名,数据类型,字长,字段是否为null以及默认值
二、利用sql
1 | CREATE TABLE 表名 |
数据表的约束
表约束
- 与列约束相互独立,不包括列定义,通常用于多个列一起进行约束,与列定义用“,”分隔,定义表约束时必须指出要约束的列的名称
列约束
- 对于特定列的约束,包含在定义中,直接跟在改列的定义中,用空格分隔,不必指明列
约束类型:
NULL/NOT NULL
表示没有数据,不确定的意思
主键列不允许出现空值
UNIQUE
- 指明基本表在某一列或者多个列的组合上的取值必须唯一 在建立UNIQUE约束的时候,需要考虑一下几个因素:
- 使用UNIQUE约束的字段允许为NULL
- 一个表中可以允许有多个UNIQUE约束
- UNIQUE约束用于强制在指定字段上创建一个UNIQUE索引,缺省为非聚集索引
- eg:设置一个S表,定义SN为唯一键
1
2
3
4
5
6
7CREATE TABLE S
(SNo VARCHAR(6),
SN NVARCHAR(10) CONSTRAINT(可省) SN_UNIQ UNIQUE,
Sex NCHAR(1),
Age INT,
Dept NVARCHAR(20)
)对上述S表定义SN+Sex为唯一键,此约束为表约束
1
2
3
4
5
6
7
8CREATE TABLE S
(SNo VARCHAR(6),
SN NVARCHAR(10) CONSTRAINT(可省) SN_UNIQ UNIQUE,
Sex NCHAR(1),
Age INT,
Dept NVARCHAR(20),
CONSTRAINT S_UNIQ UNIQUE(SN,Sex)
)表约束是单独一行
- 指明基本表在某一列或者多个列的组合上的取值必须唯一 在建立UNIQUE约束的时候,需要考虑一下几个因素:
PRIMARY KEY
- 起唯一标识作用的约束,不能重复,不能为NULL
- 在一个基本表中只能定义一个主键,大师可以定义多个UNIQUE约束
- 对于指定为PRIMARY KEY的一个列或多个列的组合,其中任何一个列都不能出现NULL值,对于UNIQUE所约束的唯一键,则允许为NULL
- 不能同一列或者一组列,既定义UNIQUE约束,又定义PRIMARY KEY约束
- eg:定义一个数据表C,定义CNo为C的主键
1
2
3
4
5CREATE TABLE C
( CNo VARCHAR(6) CONSTRAINT C_Prim PRIMARY KEY,
CN NVARCHAR(20),
CT INT
)定义SNo+CNo为SC的主键
1
2
3
4
5
6CREATE TABLE SC
( SNo VARCHAR(6) NOT NULL,
CNo VARCHAR(6) NOT NULL,
Score NUMERIC(4,1),
CONSTRAINT SC_Prim PRIMARY KEY(SNo,CNo)
)CHECK
- 用来检查字段值所允许的范围。在建立CHECK约束时,需要考虑以下的几个因素
- 一个表可以定义多个CHECK约束
- 每个字段只能定义一个CHECK约束
- 在多个字段定的CHECK约束必须为表约束
- 在执行INSERT、UNDATE、语句时,CHECK约束将验证数据
- eg:建立一个SC表,定义Score的取值范围为0~100之间。
1
2
3
4
5CREATE TABLE SC
( SNo VARCHAR(6),
CNo VARCHAR(6),
Score NUMERIC(4,1) CONSTRAINT Score_Chk CHECK(Score>=0 AND Score<=100)
)FOREIGN KEY
- 设计两个表:主表,从表
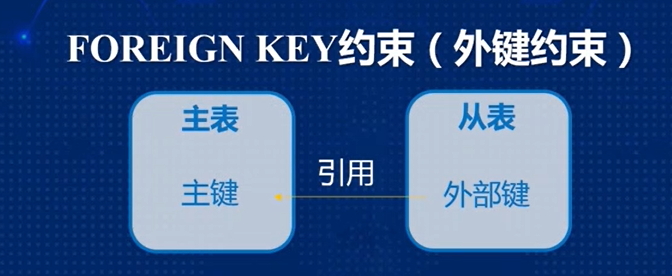
外键约束在从表中实现
eg:
建立一个SC表,定义SNo,CNo为SC的外部键
1
2
3
4
5
6
7CREATE TABLE SC
(
SNo VARCHAR NOT NULL CONSTRAINT S_Fore FOREIGN KEY REFERRENCES S(SNo),
CNo VARCHAR(6) NOT NULL CONSTRAINT C_Fore FOREIGN KEY REFERENCES C(CNo),
Soure NUMERIC(4,1),
CONSTRAINT S_C_Prim PRIMARY KEY(SNo,CNo)
)
修改数据表
一、在对象资源管理器中展开数据库节点,右键单击要修改的数据库,从快捷菜单中选择“设计”命令,则会弹出修改数据表结构对话框。可以在此对话框中修改列的数据类型、名称等属性,添加或删除列,也可以指定表的主关键词约束
二、sql命令
1 | ALTER TABLE 表名 |
使用ALTER命令修改添加数据表,自动填充为NULL值,不能为新增列提供NOT NULL约束
添加完整性约束
1 | ALTER TABLE 表名 |
对已有列进行修改,对SN加宽到12个字符
1 | ALTER TABLE 表名 |
这种情况下
- 不能改变列名
- 不能将含有空值的列定义为NOT NULL约束
- 若列表中已有数据,则不能减少该列的宽度,也不能改变其数据类型
- 只能修改NULL/NOT NULL约束,其他类型的约束在修改之前必须将约束删除,然后再重新添加修改过的约束定义
删除S表中的主键
1 | ALTER TABLE S |
删除数据表时,必须要先删除表中的约束依赖,才能删除
查看数据表:
- 查看数据表的属性
- 查看数据表数据
重点介绍sql语言查询
无条件查询:相当于只对关系表进行投影操作
eg:查询全体学生的学号、姓名、年龄段
1 | SELECT SNo,SN,Age |
查询学生的全部信息
1 | SELECT * |
加AS可以选别名,显示别名而不显示原字段
条件查询:多了WHERE字句
0查询选修课程号为“C1”的学生的学号和成绩(比较大小查询)
1 | SELECT SNo,Score |
多重条件查询:
利用NOT AND OR来进行查询
查询选修C1或者C2且分数大于等于85分学生的学号、课程号和成绩
1 | SELECT SNo,Score,CNo |
可以使用BETWEEN…AND和NOT BETWEEN….AND
查询工资不在1000元-1500元间教师的教师编号、姓名、职称
1 | SELECT TNo,TN,Prof |
模糊查询:
eg:查询所有姓张的教师的教师号和姓名
1 | SELECT TNo,TN |
查询姓名中第二个汉字是“力”的教师号和姓名
1 | SELECT TNo,TN |
空值查询:
- 空值不等同0和空格,不占任何存储空间
- 某个字段没有值称之为具有空值
eg:查询没有考试成绩的学生的学号及对应的课程号
1 | SELECT SNo,CNo |
可以借助库函数进行一些统计类的查询
eg:求学号为S1的学生的总分和平均分
1 | SELECT SUM(Score) AS TotalScore,AVG(Score) AS AvgScore |
多关系表查询:
连接查询:通过各个表中的共同字段来进行查询(连接字段)
内连接查询:
FROM后接来自不同的表
WHERE后接连接条件(共同字段相等)
例如:查询所有选课学生的学号、姓名、选课名称及成绩
1 | SELECT S.SNo,SN,CN,Score |
外连接查询:符合连接条件的数据将直接返回到结果集中,不符合连接条件的列,将会被填上NULL值后再返回到结果集。
左外连接:主表在左边称为左外连接
右外连接:主表在右边称为右外连接
例子:查询所有学生的学号、姓名、选课名称及成绩(没有选课的同学的选课信息为空)
1 | SELECT S.SNO,SN,CN,Score |
交叉连接:任何表都可以交叉连接
1 | SELECT * |
查询结果就是取和
子查询:
例子:查询与“刘伟”老师职称相同的教师号、姓名(返回一个值的普通子查询)
1 | SELECT TNo,TN |
例子:查询讲授课程号为C5的教师姓名(返回一组值)
1 | SELECT TN |
普通子查询的顺序是:先执行子查询,利用返回结果再执行父查询
相关子查询查询顺序是:先查询父查询的第一行记录,内部的子查询利用此行中相关的属性值进行查询
父查询根据子查询返回的结果判断是否满足查询的条件。如果满足条件,则把该行放入父查询的查询结果中。
重复以上过程,直至重复完父查询行数
使用exists作为关键字
例:用含有EXISTS的语句查询讲授课程号为C5的教师姓名
1 | SELECT TN |
分析:子查询的表来自于父查询
如果在TC表中的教师讲授课程号为’C5’的教师姓名不为空,那么就将T表中的这个查询取出来。
例:查询没有讲授课程号为C5的教师的姓名
1 | SELECT TN |
SQL增删改查数据
- 添加数据
例:在SC表中增加一条选课记录(’S7‘,’C1‘)【添加一行数据】
1 | INSERT INTO SC(SNo,CNo) VALUES('S7','C1') |
例:求出各系教师的平均工资,把结果存放在新AvgSal中【添加多行数据】
1 | INSERT INTO AvgSal |
- 修改数据
例:把刘伟老师转到信息系【修改一行数据】
1 | UPDATE T |
例:把教师表中工资小于或等于1000元的讲师的工资提高20%【修改多行数据】
1 | UPDATE T |
- 删除数据
例:删除刘伟老师记录【删除一行数据】
1 | DELETE |
例:删除刘伟老师授课的记录【删除多行数据】
1 | DELETE |
创建视图
- 什么是视图
视图是一个虚拟表,内容是由查询定义的
行和列数据来自自定义视图查询所引用的基本表,并且在引用视图时动态生成
例:创建一学生情况视图S_SC_C(包括学号、姓名、课程号及成绩)
1 | CREATE VIEW S_SC_C(SNo,SN,CN,Score) |
- 修改视图
例:修改学生情况视图S_SC_C(包括姓名,课程名,成绩)
1 | ALTER VIEW S_SC_C(SN,CN,Score) |
- 删除视图
1 | DROP VIEW SC |
- 查询视图
查询视图与查询表基本一致,只是FROM后面跟的是视图名称
索引
- 什么是索引
索引是一种数据库结构,通过创建索引,可以提高数据库查询和应用程序的性能
索引一旦创建,由DBMS自动管理和维护。当数据操作时,DBMS会自动更新索引
避免创建大量索引
- 索引的类型
- 聚集索引
- 表示行的物理结构与索引键的逻辑顺序相同,一个表只能有一个聚集索引
- 非聚集索引
- 与聚集索引相似,但是非聚集索引不影响表中的物理顺序
- 唯一索引
- 保证索引键不包含重复的值,从而使表中的每一行在某种方式上具有唯一性
- 视图索引
- 如果在查询中频繁的引用这类视图,可以通过对视图创建唯一聚集索引来提高性能。
- 全文索引
- XML索引
- 聚集索引
- 创建索引:
例子:为表SC在SNo和CNo中创建唯一索引
1 | CREATE UNIQUE INDEX SCi_name ON SC(SNo,CNo) |
为教师表T在TN上建立聚集索引
1 | CREATE CLUSTER INDEX TI ON T(TN) |
设计数据库
- 结构设计(子模式或者模式的设计):概念设计、逻辑设计、物理设计、
- 行为设计:用户对数据库的操作(软件设计)(动态设计)
设计法:
规范设计法:
- E-R模型的数据库模型法
- 给予三范式的数据库设计方法
- 基于视图的数据库设计方法
数据库设计的6个步骤
- 系统需求分析:收集信息内容和处理要求,进行分析
- 概念结构设计:表达用户需求的概念模型
- 逻辑结构设计:由概念模型得出的数据模型
- 物理结构设计:存取结构和存取方式
- 数据库实施:数据库入库,编写数据库存取数据
- 数据库运行和维护:收集和记录实际系统运行的数据
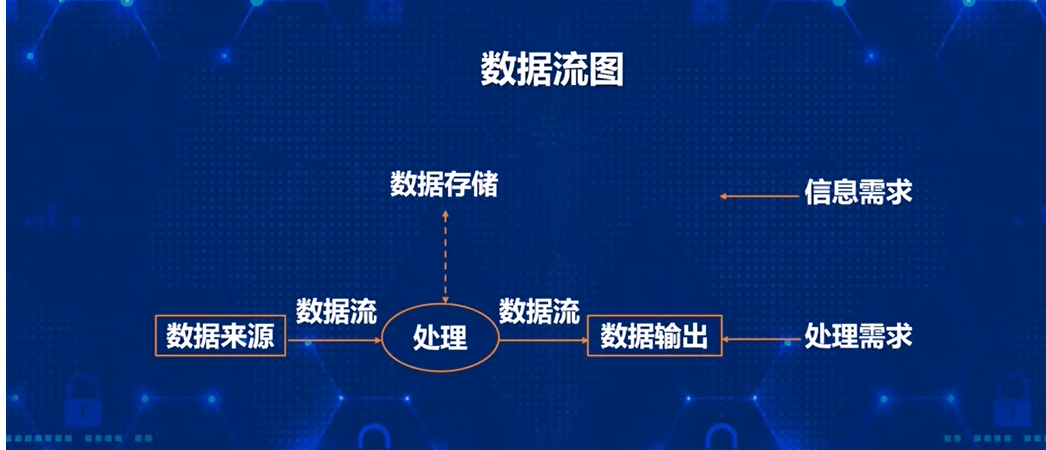
系统需求分析
需求分析方法:
- 自顶向下
- 自底向上
都需要用数据流图来进行分析
概念结构设计
通过ER图来进行设计
- 实体用矩形来表示
- 实体属性用椭圆框表示
- 联系用菱形来表示
- 实体与联系之间用无向线表示
局部ER图设计
- 属性必须是不可分的数据项,不能再由另一些属性组成
- 属性不能与其他实体进行联系,联系只能发生在实体之间
全局ER图设计
- 多元集成法
- 二元集成法
逻辑结构设计
将ER图转换成关系模式
- 将每一个实体转换成关系模式
- 将每一个关系转换成关系模式
如何将一个实体转换成一个关系模式:
实体的属性就是关系的属性
实体的码就是关系的主码
如何将一个联系转换成一个关系模式:
- 1:1联系:每一个实体的主码都是关系的候选码
- 1:n联系:n端实体的主码是关系的主码
- n:m联系:每个实体的主码的组合是关系的主码
规范化
一个好的关系模式需要具备
- 尽可能少的数据冗余
- 没有插入异常
- 没有删除异常
- 没有更新异常
函数依赖
是关系模式中属性之间的一种逻辑依赖关系